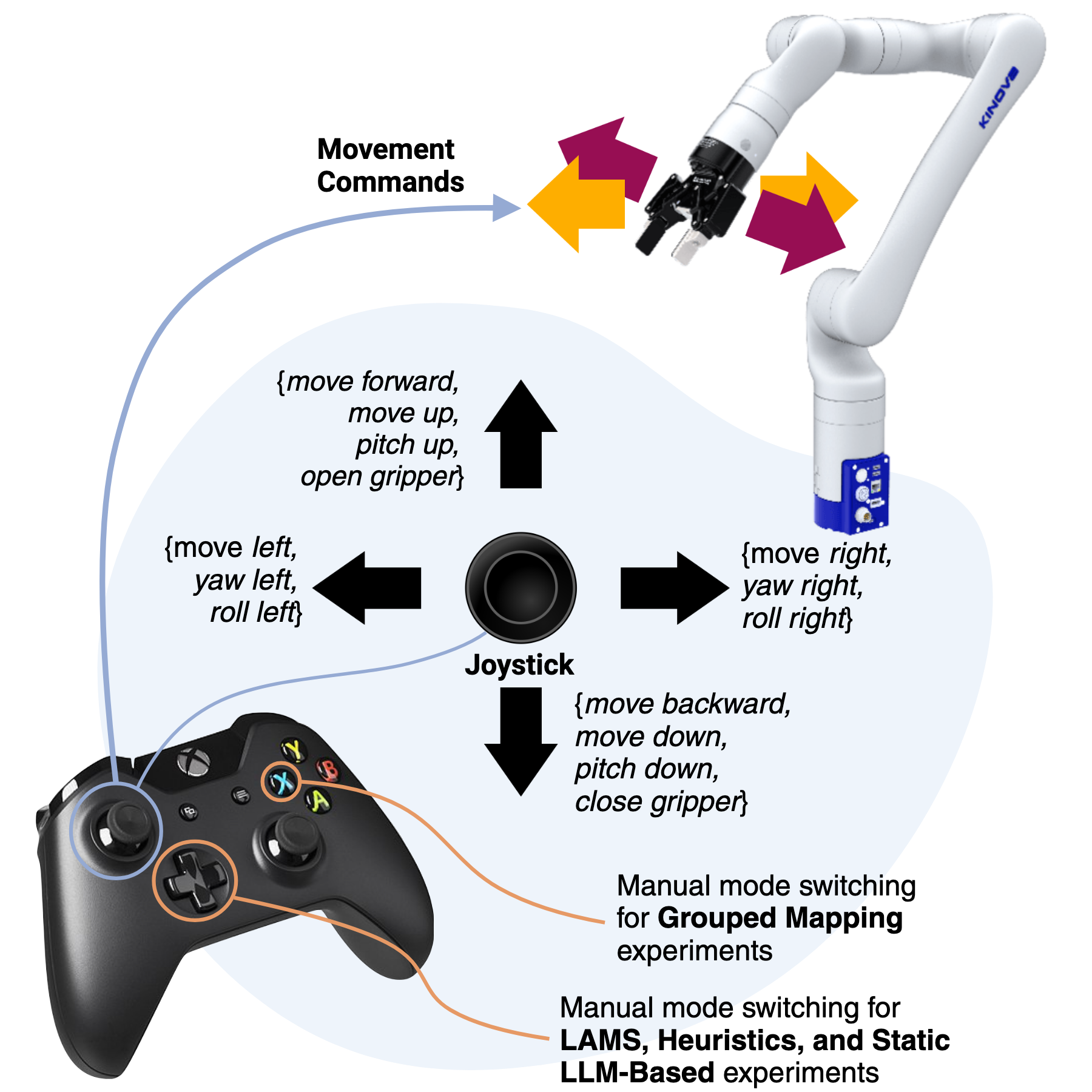
Teleoperating robotic manipulators via interfaces like joysticks often requires frequent switching between control modes, where each mode maps joystick movements to specific robot actions. This frequent switching can make teleoperation cumbersome and inefficient. Existing automatic mode-switching solutions, such as heuristic-based or learning-based methods, are often task-specific and lack generalizability. In this paper, we introduce LLM-Driven Automatic Mode Switching (LAMS), a novel approach that leverages Large Language Models (LLMs) to automatically switch control modes based on task context. Unlike existing methods, LAMS requires no prior task demonstrations and incrementally improves by integrating user-generated mode-switching examples. We validate LAMS through an ablation study and a user study with 10 participants on complex, long-horizon tasks, demonstrating that LAMS effectively reduces manual mode switches, is preferred over alternative methods, and improves performance over time.
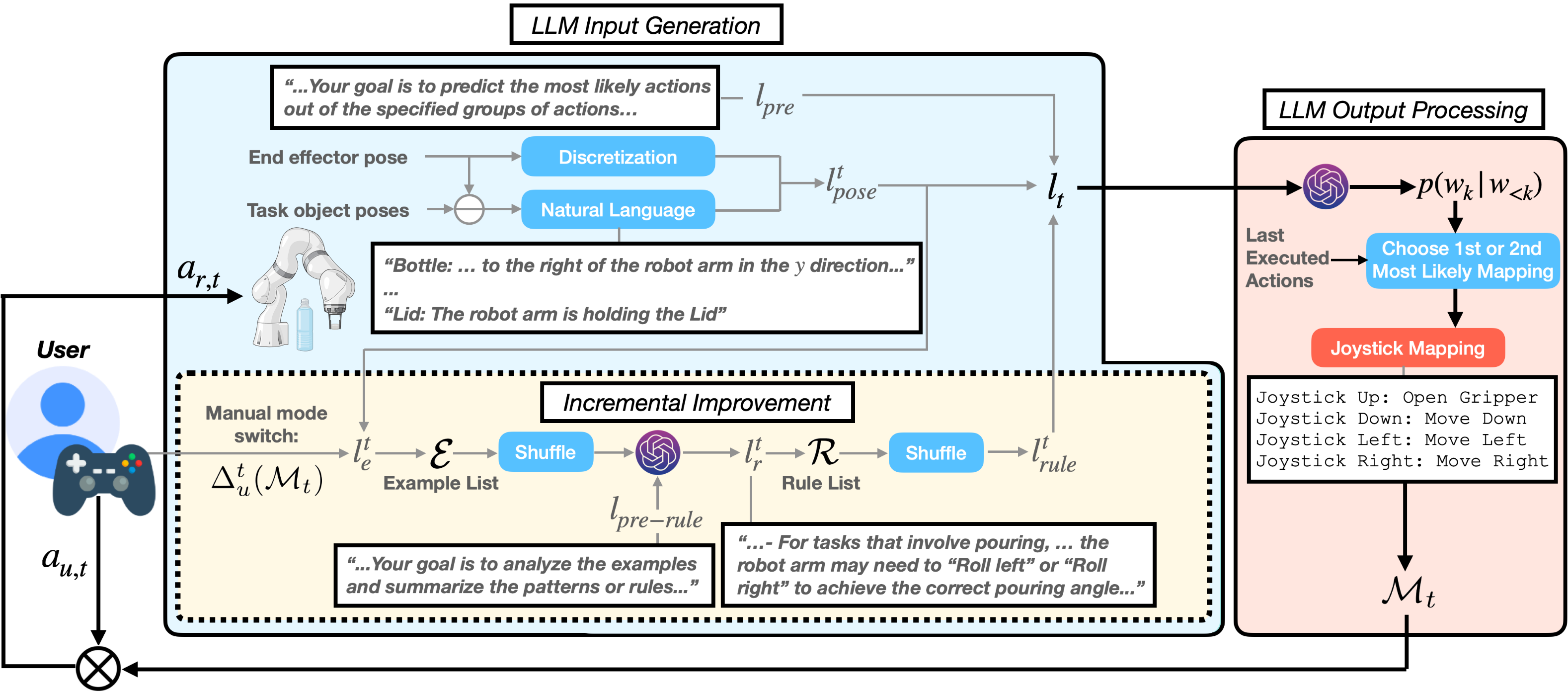
In the initial trials, while able to provide useful mapping predictions, LAMS encounters some errors due to limited task knowledge, requiring users to occasionally perform manual mode switches.
By the third trials, with LLM prompts enhanced by integrating prior user manual switches, LAMS performs automatic mode switches accurately with minimal user intervention.
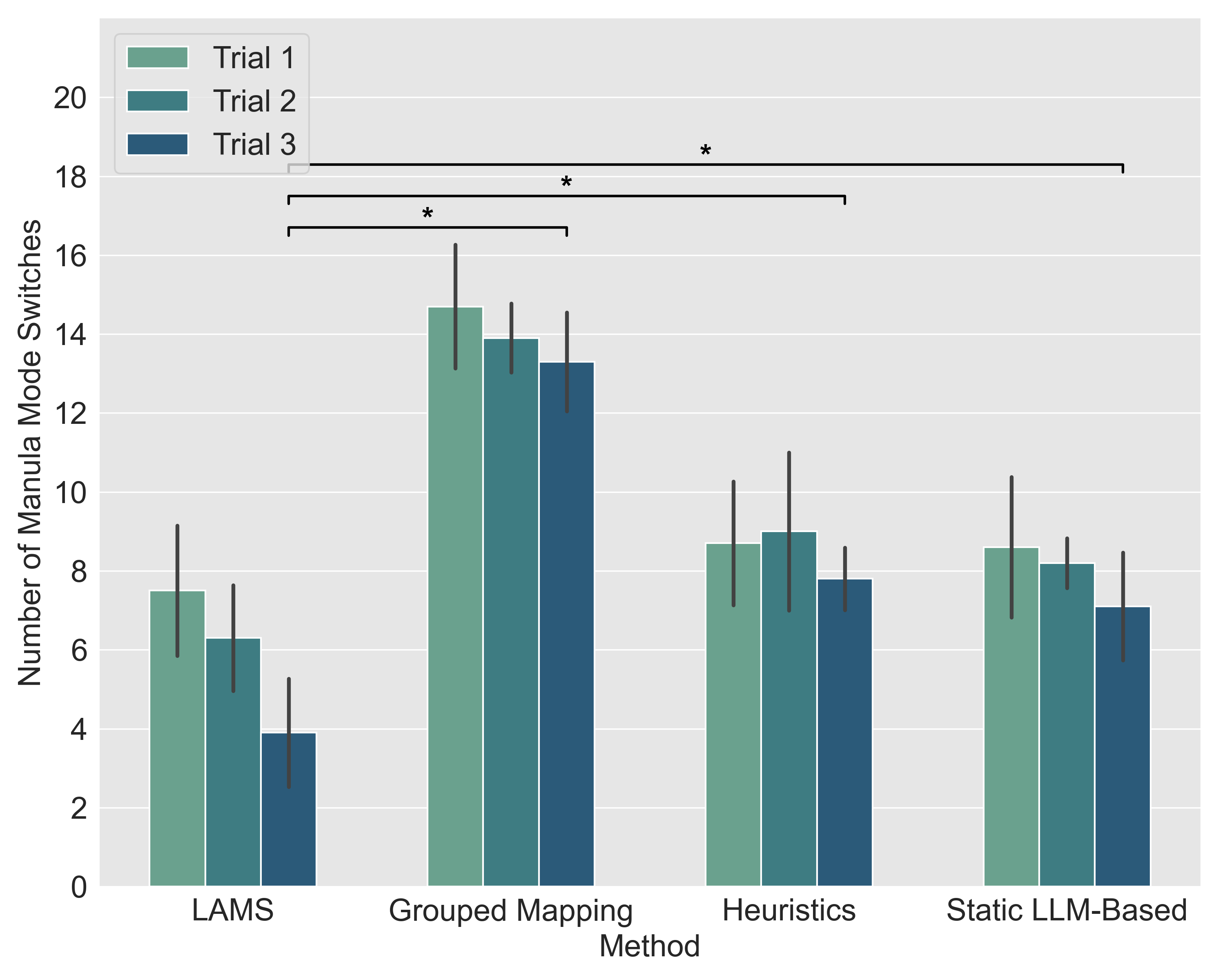
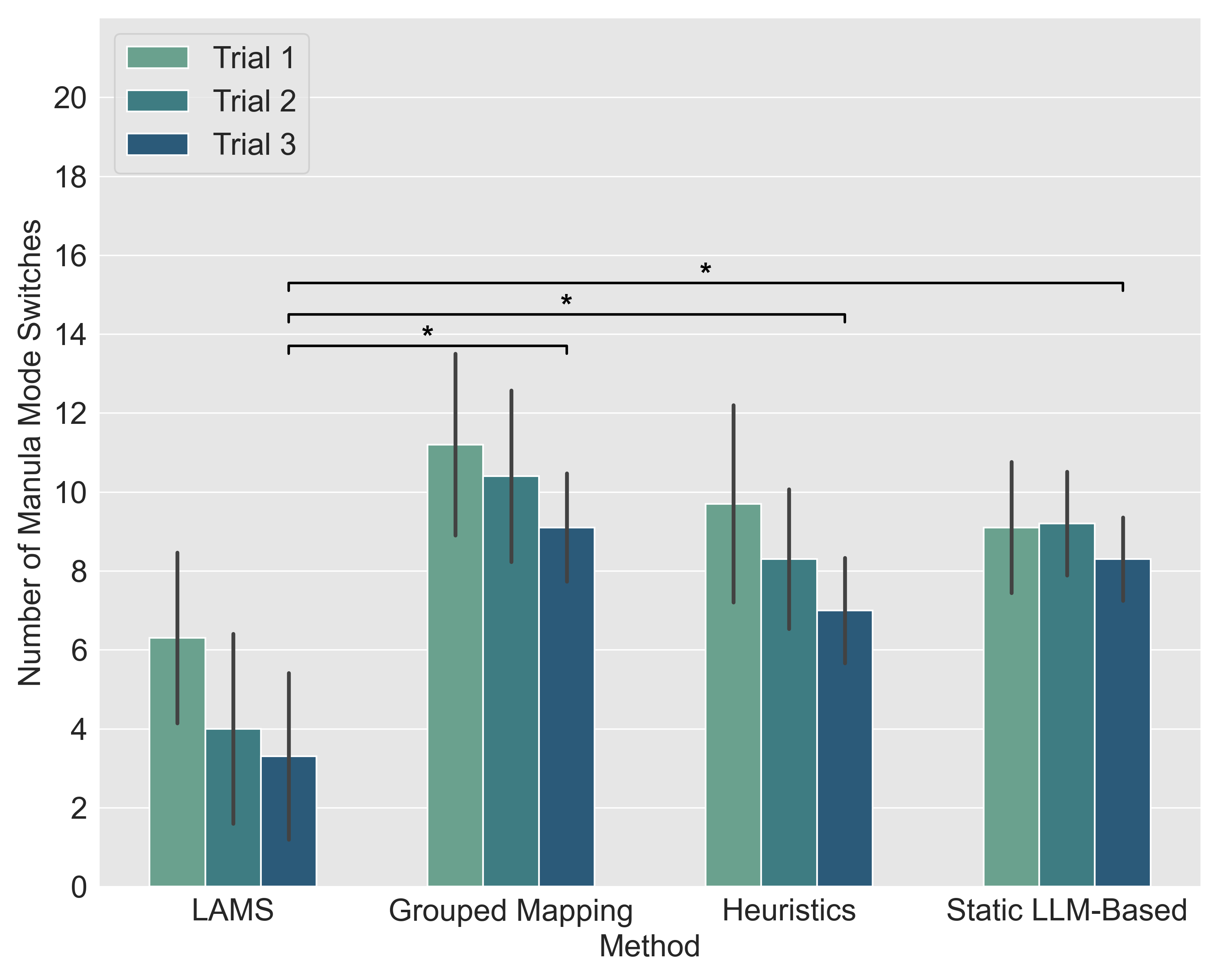
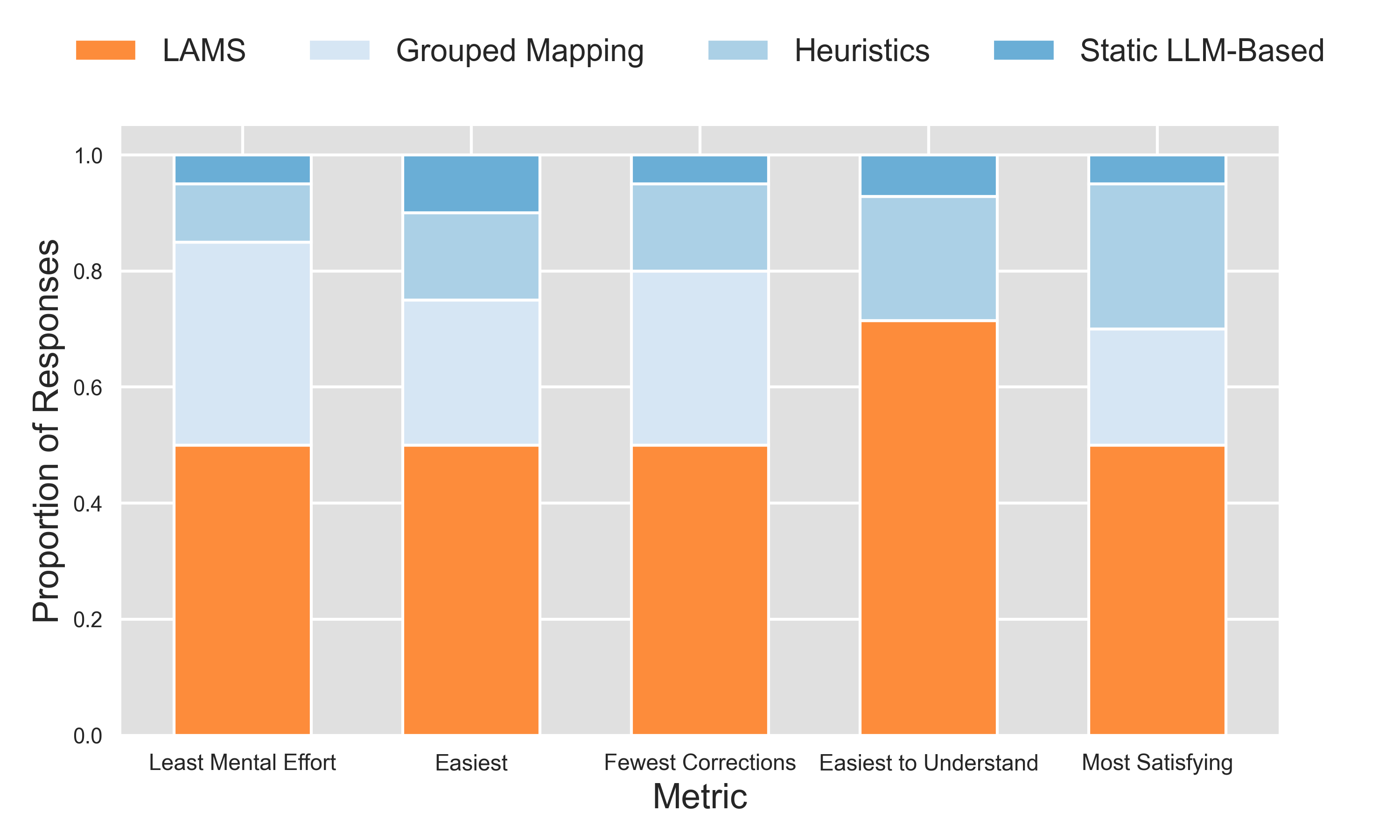 User reported preferences
User reported preferences
@misc{tao2025lamsllmdrivenautomaticmode,
title={LAMS: LLM-Driven Automatic Mode Switching for Assistive Teleoperation},
author={Yiran Tao and Jehan Yang and Dan Ding and Zackory Erickson},
year={2025},
eprint={2501.08558},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2501.08558},
}